LaMini-LM

LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, Alham Fikri Aji
![]()
![]()
![]()
![]()
![]()
LaMini-LM is a collection of small-sized, efficient language models distilled from ChatGPT and trained on a large-scale dataset of 2.58M instructions. We explore different model architectures, sizes, and checkpoints, and extensively evaluate their performance across various NLP benchmarks and through human evaluation.
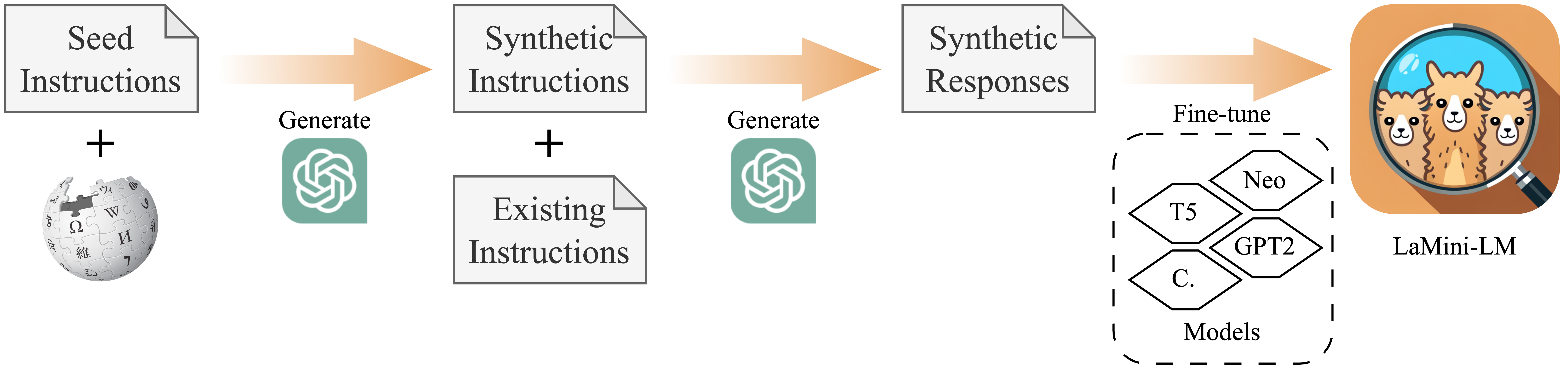
* The LaMini-LM icon was generated by Stable Diffusion.
Data
We distill the knowledge from large language models by performing sentence/offline distillation (Kim and Rush, 2016). We generate a total of 2.58M pairs of instructions and responses using gpt-3.5-turbo based on several existing resources of prompts, including self-instruct (Wang et al., 2022), P3 (Sanh et al., 2022), Flan (Longpre et al., 2023) and Alpaca (Taori et al., 2023). More information about the process for generating our instruction dataset, please refer to our paper.
We release our data HERE.
Each sample contain the following two fields:
instruction:string, describes the task that the model is expected to perform.response:string, the response to the instruction as generated bygpt-3.5-turbo.instruction_source:string, the source of a instruction. The possible values are{'alpaca', 'generated_flan', 'generated_p3', 'original_flan', 'original_p3', 'self_instruct_with_topic', 'self_instruct_without_topic'}.
Two examples in our LaMini-instruction data:
{
"instruction": "What is the capital of Australia?\n\nIs Canberra the only city chosen to serve as a capital due to a compromise between Sydney and Melbourne?",
"response": "The capital of Australia is Canberra. Yes, Canberra was chosen as the capital of Australia in 1908 due to a compromise between Sydney and Melbourne, as neither city wanted the other to become the capital.",
"instruction_source": "generated_flan"
}
{
"instruction": "Create a poem that has the word \"ocean\" in every other line.",
"response": "The ocean's depth is a mystery,\nIts waves crashing with energy.\nSalt air fills the coastal scene,\nThe ocean's blue hues pure and clean.\n\nSeagulls cry out a melancholy song,\nThe ocean's rhythm steady and strong.\nSunsets paint the water gold,\nThe ocean's secrets forever untold.",
"instruction_source": "self_instruct_without_topic"
}
Models
You can download LaMini-LM series as follows. Models with ✩ are those with the best overall performance given their size/architecture, hence we recommend using them. More details can be seen in our paper.
| Base model | LaMini-LM series (#parameters) | |||
|---|---|---|---|---|
| T5 | LaMini-T5-61M | LaMini-T5-223M | LaMini-T5-738M | |
| Flan-T5 | LaMini-Flan-T5-77M✩ | LaMini-Flan-T5-248M✩ | LaMini-Flan-T5-783M✩ | |
| Cerebras-GPT | LaMini-Cerebras-111M | LaMini-Cerebras-256M | LaMini-Cerebras-590M | LaMini-Cerebras-1.3B |
| GPT-2 | LaMini-GPT-124M✩ | LaMini-GPT-774M✩ | LaMini-GPT-1.5B✩ | |
| GPT-Neo | LaMini-Neo-125M | LaMini-Neo-1.3B | ||
| GPT-J | coming soon | |||
| LLaMA | coming soon | |||
Using Models
LaMini-LM series and instruction dataset are intended for research use only. (CC BY NC 4.0)
We recommend to use model to reponse to human instructions wrote in natural language.
We now show you how to load and use our model using HuggingFace pipeline().
Encoder-Decoder Models
# pip install -q transformers
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text2text-generation', model = checkpoint)
input_prompt = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
Decoder-Only Models
For decoder-only models, we used a instruction wrapper to train the model. Hence, we should use the wrapper at inference time.
# pip install -q transformers
from transformers import pipeline
checkpoint = "{model_name}"
model = pipeline('text-generation', model = checkpoint)
instruction = 'Please let me know your thoughts on the given place and why you think it deserves to be visited: \n"Barcelona, Spain"'
input_prompt = f"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{instruction}\n\n### Response:"
generated_text = model(input_prompt, max_length=512, do_sample=True)[0]['generated_text']
print("Response", generated_text)
Evaluation
NLP Evaluation
We use language model evaluation harness (lm-evaluation-harness) to evaluate our instruction-tuned models. We select 15 diverse NLP tasks, including multiple-choice QA, sentence completion, and sentiment analysis, etc.
Details about evaluation datasets (Click to expand)
| Clusters | Dataset | Size | Metric |
|---|---|---|---|
| Multiple-Choice QA | OpenBookQA | 500 | accnorm |
| SciQ | 1,000 | accnorm | |
| RACE | 1,045 | acc | |
| ARC-C | 1,172 | accnorm | |
| PIQA | 1,838 | accnorm | |
| Extractive QA | ReCoRD | 10,000 | F1 |
| Sentiment Analysis | SST | 872 | acc |
| Paraphrase Identification | MRPC | 408 | acc |
| NLI | RTE | 277 | acc |
| MNLI | 9,815 | acc | |
| MNLI (mis) | 9,832 | acc | |
| Coreference Resolution | WSC | 273 | acc |
| WinoGrande | 1,267 | acc | |
| Word Sense Disambiguation | WiC | 638 | acc |
| Sentence Completion | HellaSwag | 10,042 | accnorm |
The performance comparison between encoder-decoder models and decoder-only models of LaMini-LM family on the downstream NLP tasks. The horizontal dash lines indicate the average performance given by Alpaca-7B and LLaMa-7B.
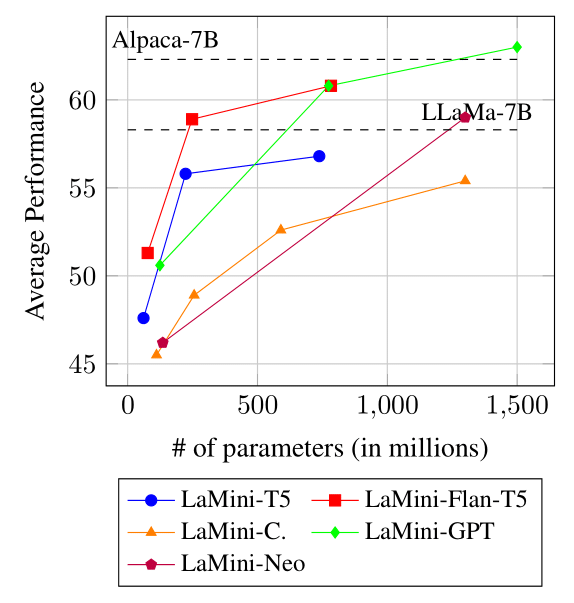
Warning **The reported LLaMA results are not comparable to ours**, as the LLaMA authors did not provide sufficient details for reproducible evaluation. We use lm-eval-harnesss to measure the performance. You can replicate the result yourselves. As for our LaMini-LM decoder-only models, we modify lm-eval-harness to add prompt wrapper for each instruction. You can use our bash script to run the evaluation.
Human Evaluation
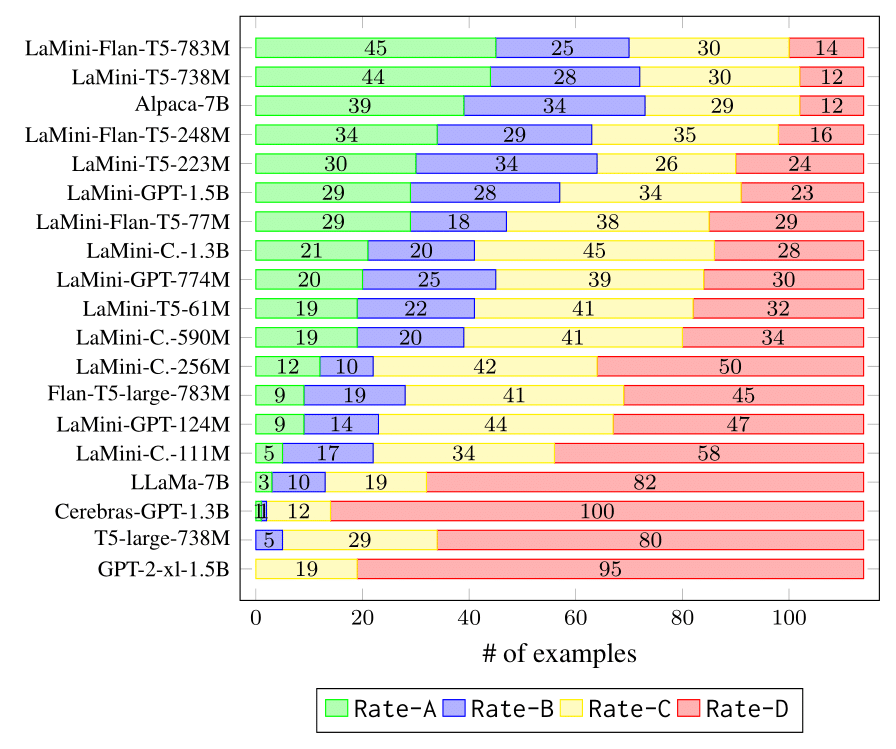
Human evaluation results of the selected models on our 114 user-oriented instructions.
- Rate-A: Valid, acceptable and satisfying;
- Rate-B: The response is acceptable but has minor errors that can be improved;
- Rate-C: The response is relevant and responds to the instruction, but it has significant errors in the content;
- Rate-D: Invalid and unacceptable response.
Qualitative Analysis
Model responses to the instruction Include important study notes and key points that someone should know about the given subject: "history of the USA", where Alpaca-7B fails but LaMini-LMs manage to respond. The high-quality contents are highlighted in blue. The errors are highlighted in red.

Model responses to the instruction Write a short description about the given movie or series: "The Witcher (2019)", where LaMini-LMs fails but Alpaca-7B manages to respond. The high-quality contents are highlighted in blue. The errors are highlighted in red.

Citation
Please cite us if you use our data or models.
@article{lamini-lm,
author = {Minghao Wu and
Abdul Waheed and
Chiyu Zhang and
Muhammad Abdul-Mageed and
Alham Fikri Aji
},
title = {LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions},
journal = {CoRR},
volume = {abs/2304.14402},
year = {2023},
url = {https://arxiv.org/abs/2304.14402},
eprinttype = {arXiv},
eprint = {2304.14402}
}